令和初の投稿です。Lesson5はやっと本番というか学びたいところに到達したという感じです。画像分類の主流(らしい)CNN!例によってスタンフォード大学のCS231nを訳しています。
畳み込みニューラルネットワーク(Convolutional Neural Networks :CNN)
畳み込みニューラルネットワークは、前の章の通常のニューラルネットワークと非常によく似ている:学習可能な重みとバイアスを持つニューロンで構成される。各ニューロンはいくつかの入力を受け、ドット積をとり、任意に非線形性をもってそれに従う。そのネットワークの全体は単一の微分可能なスコア関数で表現できる:一方の生画像ピクセルからクラススコアまで。そして、最後の(全て接続された)層に損失関数(例えばSVMやSoftmax)もあり、通常のニューラルネットワークを学ぶために開発した全ての助言/トリックも適用できる。
ではどこが違うのか?CNNアーキテクチャは入力が画像であるとはっきりと仮定するが、それによってアーキテクチャに特定の属性をエンコードできる。これらは准伝搬関数を実装するのにより効率的で、ネットワークのパラメータを劇的に減らすことができる。
アーキテクチャの概要
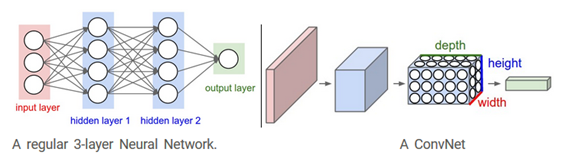
前節でみたように、ニューラルネットワークは入力(1つのベクトル)を受け、連続した隠れ層を通じて変形される。各隠れ層はニューロンのセットでできている。ここで各ニューロンは前の層の各ニューロン全てと接続されており、ある1つの層のニューロンは完全に独立して働き、接続をシェアしていない。最後の層は“出力層”と呼ばれ、分類器では分類スコアを表している。 通常のニューラルネットワークはフルイメージへの適用は向いていない。CIFER-10では画像は32×32×3(幅32、高さ32、3色)のサイズしかなく、通常のニューラルネットワークの第一隠れ層の完全接続ニューロンは32×32×3=3072の重み付けをもつ。この規模ならまだ扱えそうだが、明らかにより大きな画像では扱いきれないだろう。さらに、我々はほぼ確実にそのようなニューロンをいくつか持ちたくなり、パラメータはすぐに増える。明らかに完全接続は無駄が多く、非常に多くのパラメータはオーバーフィットになりやす い。
3Dボリュームのニューロン。畳み込みニューラルネットワークは、入力が画像で構成されているという事実を利用し、より賢明な方法でアーキテクチャを制約する。特に、通常のニューラルネットワークとは異なり、ConvNetのレイヤーには、幅、高さ、深さの3次元に配列されたニューロンがある。 (ここでの深さという言葉は、フルニューラルネットワークの深さではなく、アクティベーションボリュームを指していることに注意。これは、ネットワーク内の層の総数を指すことができる。)たとえば、CIFAR-10の入力画像はアクティベーションの入力ボリュームであり、ボリュームのサイズは32×32×3(それぞれ幅、高さ、奥行き)。下図のように、ある層の中のニューロンは、すべてのニューロンが完全接続される通常のニューラルネットワークに対して、ConvNetはその前の層の小さな領域にのみ接続される。さらにCIFAR-10用の出力層は1x1x10の次元である。なぜなら、ConvNetアーキテクチャの最後には画像のピクセルを分類スコアの単一ベクトルに落とし込むからである。